")
")



TomNomNom is a security researcher and bug bounty hunter. you must have seen him at Nahamsec’s talk where he explains his methodology and shows how he approaches the target, enumerates subdomains and exploit the vulnerabilities. I think he is really good at automation with the Linux shell. In this article, we are going to use these tools and see how it is working made by TomNomNom. Before you read any further let me clear one thing I am not familiar with GoLang, so I will try my best and will focus on just logic more.
Most of the tools that he has created can be used or should I say being used in bug hunting on websites. Tools are written in GoLang as it is fast and can be used with or without compilation. Each tool is used in a specific condition.
You may have even used this tool before because this is a really famous tool of TomNomNom. It is used in subdomain enumeration.
sudo su -
go install github.com/tomnomnom/assetfinder@latest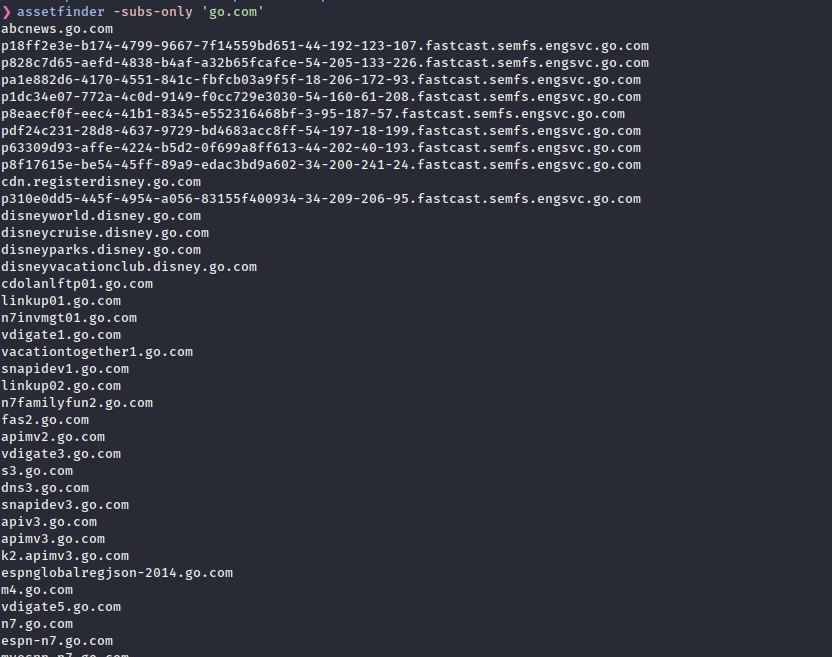
The use of this tool is quite easy. The command would be assetfinder -subs-only example.com. It will start finding the subdomains from various sources like Facebook, urlscan etc. we can check the available sources it uses on its GitHub. For example, I can look into the code of crtsh source code.
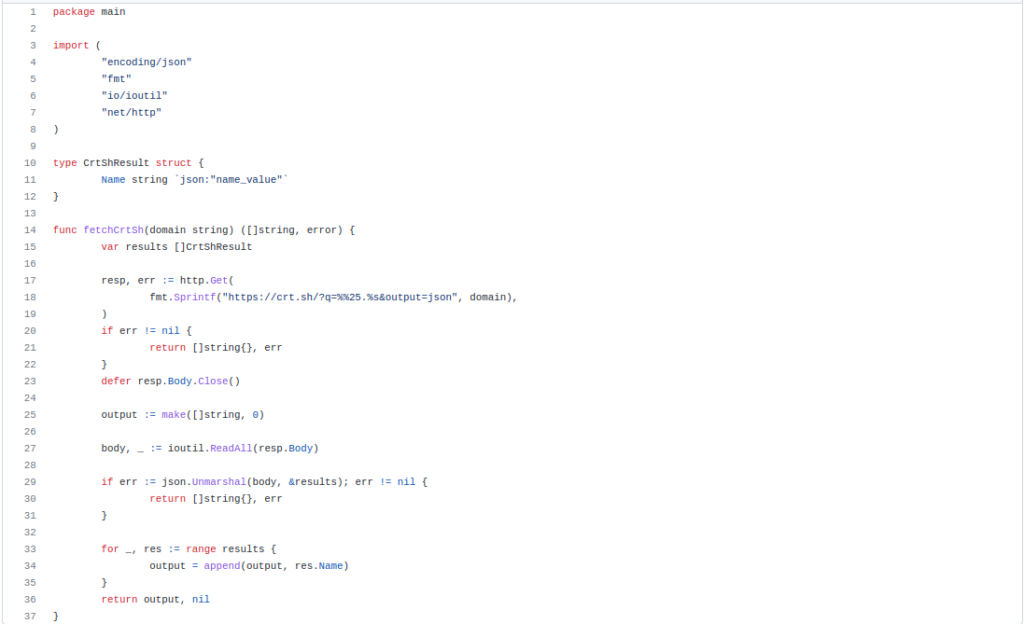
look at the line 18 URL, it seems that it is manually supplying queries to the website using sprintf function. It is one of those scripts the assetfinder is using, there are more of them.
httprobe is used for checking if there is an HTTP service running on the domain. By default, it checks for the 80 and 443 ports on the domain but we can include more ports using -p flag. I personally like to use it with assetfinder tool. I directly pipe the output of the assertfinder to the httprobe.
assetfinder -subs-only 'go.com' | httprobe --prefer-https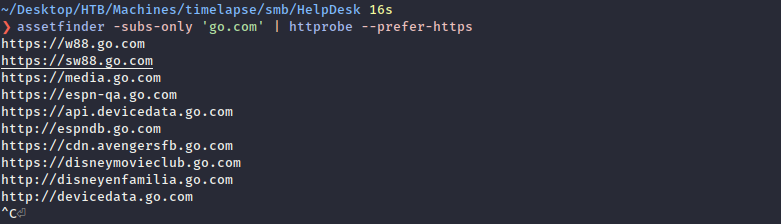
The –prefer-https flag is to include only the https scheme result for a domain, not the HTTP one.
meg is a really important tool in the enumeration. We use this tool to request one or more than one endpoint (taken from a file) on the single or multiple hosts (taken from a file). we can store the results of each host in a separate directory. you can check for more options of meg using –help flag. you can just put all the hosts into the `hosts` file and paths into the `paths` file. and after this, you can run this command simply.
meg -c 200 -L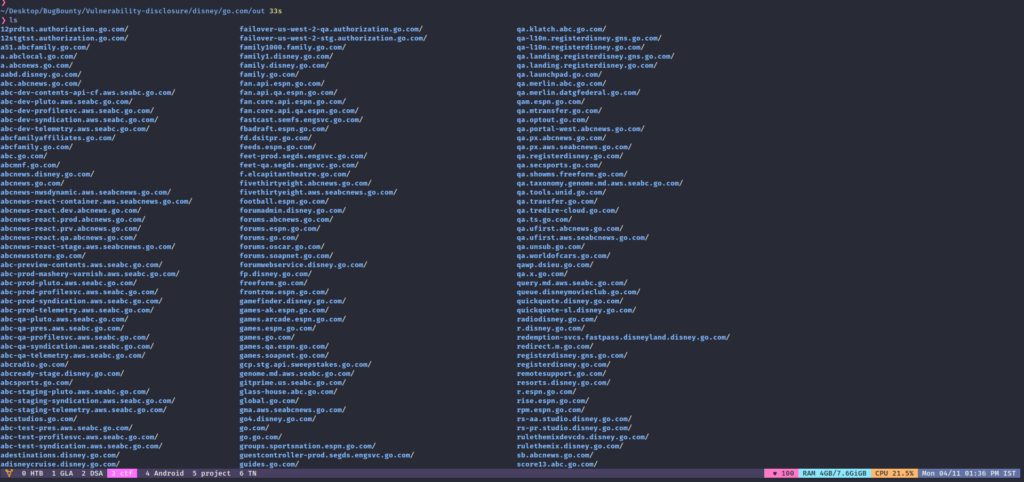
Here -L flag is to follow the redirects and -c is for concurrency. After execution of this command, you can find the results in `out` directory.
The next tool I like using is gf which is a tool to filter results, pick the URLs or maybe the URLs with GET parameter that may lead to some ssrf attack. This tool uses its own config files. these config files are JSON files containing flags for grep (Hnri) and the regex pattern. There is a GitHub repo GF-Patterns which has some amazing config/patterns files for gf. Think of a scenario, you have used the meg tool on 1000 targets and now you want to grep for ssrf endpoints from the result. You could run the following command.
find ./out -type f | gf base64 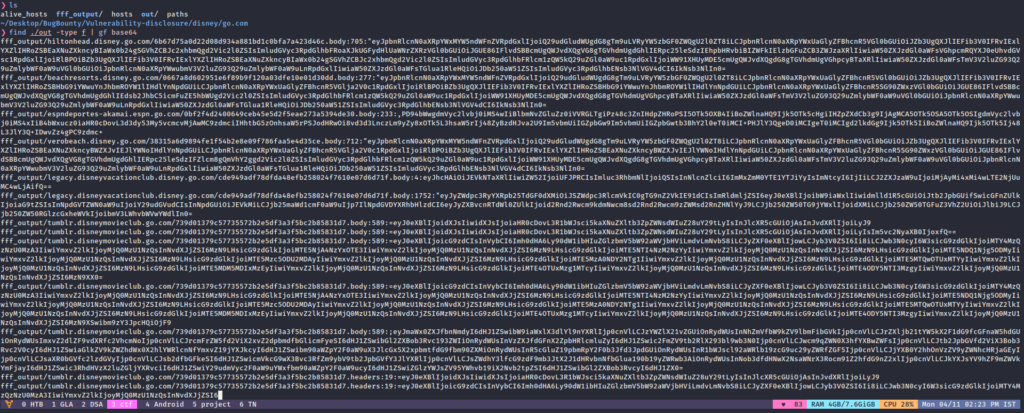
the find command will result out every single find exists in the out directory and will send the input to the gf tool that will run some regex using grep command.
gron is a tool to grep JSON output in a more efficient way. we can grep the value of a specific key from JSON output. And the best thing is that it has colours in the output. You can save the gron tool output and then ungron it to get the JSON output back. gron tool even works as an HTTP client.
curl -s "https://api.github.com/repos/tomnomnom/gron/commits?per_page=1" | gron >/tmp/king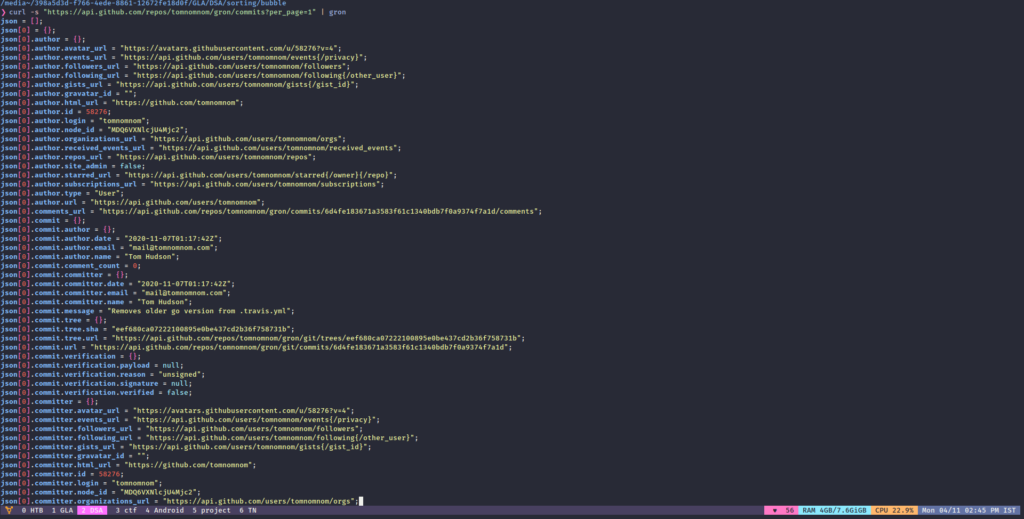
We have made it greppable. one can easily look for the commit values or maybe authors, emails, node_id etc.
If you think that your dirbuster/gobuster is not good enough for your target enumeration and you think that there may exist more hidden files and directories over a host, you can use this tool to enumerate more endpoints from the internet. it uses this webarcv website in order to get the result.
the simple logic behind this go script is the following one (implemented in bash).
#!/bin/bash
ENDPOINT=$1;
curl -s https://web.archive.org/cdx/search/cdx?url=$ENDPOINTBut since we are talking about the Tomnomnom tools, waybackurl does the same thing. You can even do the same using a web browser.
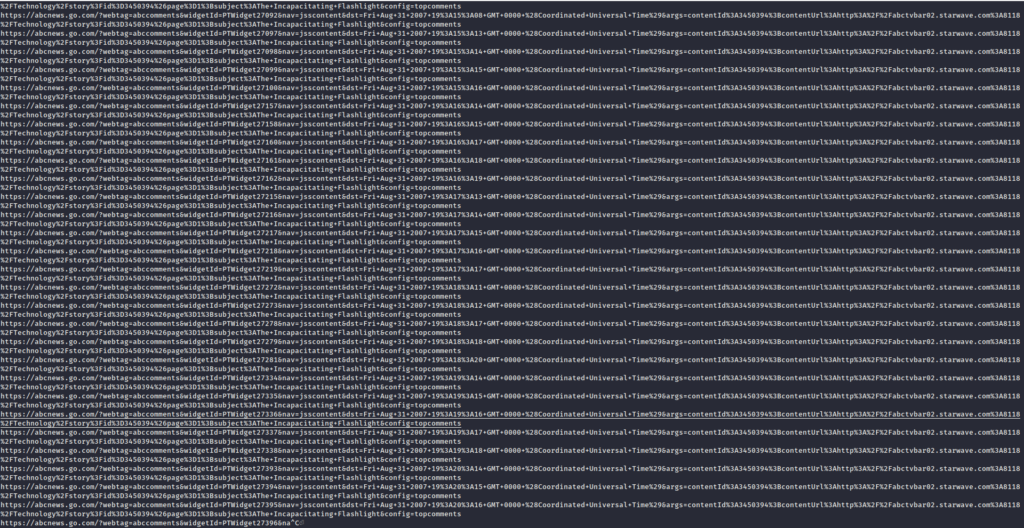
You can use all of these tools altogether in bash and perform a better-automated enumeration on your target.



")





")


{kind=link}